


Heroes of Data: 2022's top 5 data trends according to 5 top data leaders - Part 1
Heroes of Data is an initiative by the data community for the data community that shares the stories of everyday data practitioners and showcases the opportunities and challenges that arise daily. Sign-up to our newsletter today and never miss an update!
The buzz around data and especially the Modern Data Stack continues to grow. The concept around the Modern Data Stack (albeit still in its early innings) is tightly connected with the explosion of data tools in the cloud. Billions of dollars have been invested in startups in 2021 and 2022 aiming to solve different problems in the modern cloud-first data stack. The cloud comes with a new model of infrastructure that will help us build these data stacks quickly, programmatically, and on-demand, using cloud-native technologies like Kubernetes, infrastructure as code like Terraform and DevOps best practices for cloud.
But what direction are we really moving in and where are we going? What are the data trends that are here to stay, according to data practitioners who get their hands dirty every day? And looking to the future, what comes next?
For this inaugural Heroes of Data article, we asked 5 data operators from modern cloud-first organizations and fast-growing scaleups the following: What trends will define the data landscape in 2022 and beyond? Note that everyone had several data trends they wanted to highlight. In order to keep this article more easily digestible, however, we asked them to stick to just one.
This is the first part of a series of articles covering the latest trends in the world of data as observed by those in the data community – with a focus on operators building scalable cloud-first data infrastructure in modern data-driven organizations.
The first Heroes of Data to share their insights are:
Magnus Dahlbäck, Head of Data Analytics, VOI
Karim Hamed, Staff Engineer, Truecaller
Samantha Lam, Head of Analytics, Mentimeter
Lars Nordin, Head of Data Engineer and BI, Sambla
Marcus Svensson, Head of Data Science, Babyshop Group
Scroll down to get more insight on their knowledge and don’t forget to subscribe to get access to part 2! Know of anyone who should be featured? Feel free to reach out to us at hi@heroesofdata.com to let us know!

Data Trend 1: Rise of the metrics layer
Magnus Dahlbäck, Head of Data Analytics, VOI
People don’t care about granular data tables or the most beautiful dashboards. In the end, they care about the metrics that measure the business. But metrics are often not treated with the attention they deserve, resulting in unclear definitions, inconsistent numbers and overall poor trust in data.
The technical solution to this long-lasting problem (which is also about processes) is found in Metric Store/Layer, and might be the biggest gap in the modern data stack in my opinion. If it can live up to its promises, it will enable easy, trustworthy and tool-agnostic consumption of metrics without needing to know how the metrics are defined or pre-calculating all possible permutations of dimensions. For example, getting the correct number of Active Voi Riders by Week with Year-over-Year in % for Sweden is a matter of a few clicks, a simple SQL query or a straightforward API call.

There are lots of interesting products (dbt Metrics, Transform.co, MetriQL, to name a few) emerging in this area and it’s definitely on Voi’s radar. At Voi, we’re halfway to solving this problem, as we have governed definitions, appointed owners and implemented a single source of truth for our top 50+ metrics. We just need to solve the consumption part.

Data Trend 2: Data observability and the rise of the data fabric
Karim Hamed, Staff Data Engineer, Truecaller
Data observability and data fabric are two separate topics that only properly work when combined. I see a trend where companies are realizing the value of investing into applying data observability and building a data fabric, which allows them to have a better holistic view and access to the data, be more data-driven and more efficient in extracting value from data across the organization.
In summary, data observability is all about observing and monitoring your data. This can range from gathering metadata, understanding the data lineage, profiling, assessing quality and governing your data. This empowers data citizens to be able to discover the data available for their analytics, be able to identify what to trust and understand the health of the data. It should allow them to answer many questions, such as: What tables do I have? How were those tables created? Who created them? Who's accessing them? Can I trust this data? What is the quality of the data? How fresh is it? And many more.

Data fabric, on the other hand, is an integrated architecture and a set of services that, if implemented, creates a standardized data management layer across environments. This allows you to take advantage of your data no matter where it’s stored. It can empower you with visibility, access control and security for your data, regardless of where it is (on-premise, cloud, hybrid or multi-cloud). A data fabric ensures that any data on any platform and any location can be successfully combined, accessed, shared, and governed efficiently and effectively.

Data trend 3: Tools for agile data science teams
Samantha Lam - Head of Analytics, Mentimeter
Getting different data disciplines to work efficiently together will be a competitive advantage for companies to retain talent. It's all fun and games until working on a data team becomes so disconnected and isolating that you don't care anymore and move to another company in hopes of greener pastures. While there has been some progress with borrowing Agile methodologies, such as in data engineering, where there’s clearer expertise overlap, this is a well-known ongoing problem for data science and analysts. Even so, with the advent of data products/viewing data as a product, these ideas challenge how data teams are run, even on the engineering level.

Some key things that are hard to address:
Discovery/research work vs. production/stakeholder-ready
How to peer review
Roles and progression
While the last challenge is largely an internal one, the other two are open for disruptors in the tool space – the forever cycle of discovery vs. production has been a frequent topic of many meetup and roundtable-type discussions, but no general methodology equivalent to the Agile manifesto has emerged. On the peer review side, some tools have already started acknowledging this need (e.g. notebooks that allow easy sharing and commenting, such as Hex.tech). It will be an exciting time when there comes a Jira/Trello equivalent for data science.

Data Trend 4: The continuous evolution of ETL
Lars Nordin, Head of Data Engineering and BI, Sambla
One of the things I look forward to watching unfold in 2022 is the evolution of ETL. The way I see it, it’s being pushed forward by three key drivers:
Business need: we want ETL to ultimately support business insights and actions, hence how it's evolved accordingly.
Technological advancements: improved technical functionality, performance and storage can help push ETL towards its true essence (with the ‘T’ as transforming data into business insights and actions).
Operational efficiency: we want the process of developing our ETLs to satisfy our needs of productivity, collaboration, security, etc., whether it’s code or no code.
The last couple of years has seen ETL evolve in all the above areas:
The need for business actionability has given us no-code ETL tools, ‘reverse ETL’ technologies and lately, the concept of a centralized metrics layer.
Technological advancement has given us tremendous performance in transforming huge amounts of data, which among other things, allows us to do ELT, real-time analysis on streamed data, as well as implement emergingLakehouse technologies.
And our search for operative efficiency has evolved into tools, such as dbt and Dataform, in addition to processes and organizational designs, such as data mesh – all of which have a considerable impact on how we choose to work with our ETLs.
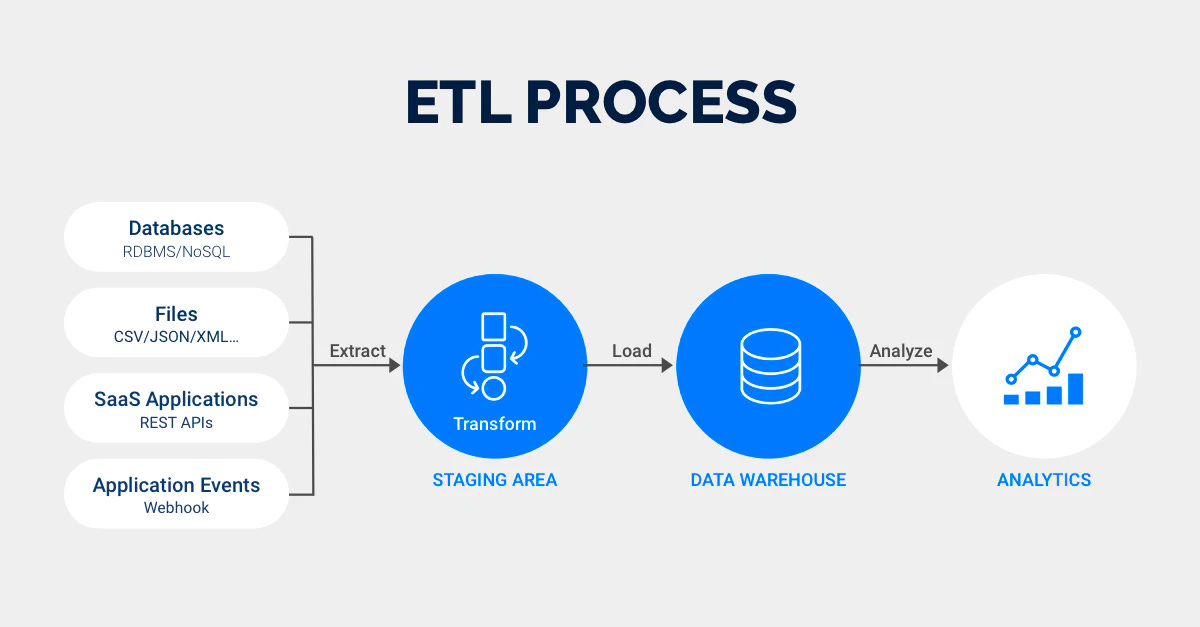
In 2022, I believe we will see a convergence of many of the latest ETL developments. Some will happen through acquisitions and vertical integrations, and some will happen with the help of strong companies and communities shaping technologies and refining best practices. By the end of 2022, I wouldn't be surprised if the ETL acronym itself is challenged by a better naming convention because already today, ETL feels quite outdated as the lines between the ‘E’, ‘T’ and ‘L’ have become more and more blurred.

Data Trend 5: Rise of streaming tools
Marcus Svensson, Head of Data Science, Babyshop
During the last few years, there has been an increased interest in streaming data. This has primarily been driven by the increase of IoT sensors, server and security logs, real-time advertising and clickstream data to mention a few, which have put new demands and requirements on the data infrastructure needed. This has in turn increased the popularity and interest of streaming frameworks, one being the Publish-Subscribe pattern, leveraged by tools such as Apache Kafka, Pub/Sub and Amazon Kinesis.
While the trend of streaming data by no means shows any signs of slowing down, what I personally see in this space is the emergence of applications and usage particularly focused within the Publish-Subscribe space; in particular, the internal data flow in (consider, for example, an ecommerce platform with regards to product information, prices and stock levels). This data might have been stored in fairly large databases historically that consumers of the data had to query. Leveraging a Publish-Subscribe system (e.g. Apache Kafka), this data flow can instead be orchestrated via different topics. These topics then publish changes ( e.g. of stock levels) that interested parties (front-end UI, cart, CRM, etc.) can subscribe to. This way, a single source of truth of the data exists, and fairly light-weight API's can be built on top of these streams to store their current state (i.e. the current stock of all products).
Moreover, since every consumer application of each topic is independant, the software applications leveraging this data becomes decoupled by default, which has its own benefits. Moving away from databases to store the ‘latest’ data, and instead, towards a stream-focused data layout, I see this orchestration becoming more and more popular. It will be a strong data trend in 2022 and beyond when improving existing and building new applications.

There are many benefits with such a setup, such as latency and data quality, but this data orchestration inherently exposes new challenges. A historized data warehouse, mostly used for BI and analytics, needs to consume streams of data, hooked up directly to these topics, leveraging a change-data-capture streaming setup, instead of the previous periodic ‘batch-like’ data loading (e.g. Fivetran). Because of this, most data usage, such as validation, needs to be performed on streams instead of batch, which poses other types of challenges. Furthermore, such data streams allow for near real-time analytics, which allows for the creative consumer to leverage data in a way that wasn’t possible before. As always, new ways of working with data pose new challenges, how fun would it be otherwise?
Final thoughts
From the building of teams to the bundling of tools, it’s clear that the data ecosystem is set for some major changes in the coming year. For a quick recap, the five trends covered in this article were:
The rise of the metrics layer
Data observability and the rise of the data fabric
Tools for agile data science teams
The continuous evolution of ETL
The rise of streaming tools
We hoped you enjoyed these Heroes of Data insights. Eager to learn more and glean into the experience of seasoned data veterans? Remember to subscribe and stay tuned for part 2 of this series, and more to come!